
 400-626-7377
400-626-7377
大模型具備適用于眾多場景的泛化能力
大模型的泛化能力是其核心優勢之一,使其能夠突破單一任務或領域的限制,靈活適配多樣化的現實需求。以下是這一能力的關鍵支撐因素及典型表現:
一、泛化能力的底層邏輯
1、海量數據的隱性知識編碼
世界知識的壓縮存儲:通過萬億級Token的預訓練,模型隱式學習了語言結構、常識推理、專業知識(如醫學、法律)甚至文化背景,形成覆蓋廣泛領域的“通用知識庫”。
2、參數化的語義空間映射
向量空間的連續性:大模型將離散符號(文字/圖像)映射到高維連續空間,相近語義的對象在空間中聚集。這種幾何特性使模型能處理開放式問題。
應用:查詢擴展——輸入“減肥食譜”可聯想至“低卡路里”“高蛋白”等關聯概念。
3、元學習的自適應機制
快速校準的新場景遷移:微調階段只需少量樣本即可調整參數分布,本質是通過梯度下降在新任務附近尋找最優解邊界。
二、跨維度的泛化表現
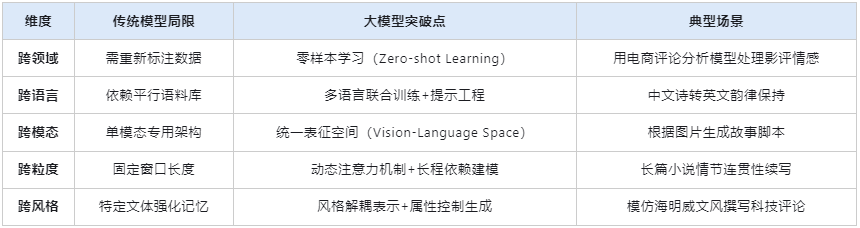
三、實現泛化的關鍵技術路徑
1、自監督學習的涌現效應
無標注數據的威力:通過Masked Language Modeling (MLM)、Next Sentence Prediction (NSP)等任務,迫使模型主動構建語義關聯網絡。
2、提示工程
指令即接口:通過精心設計的輸入模板引導模型行為,無需修改底層參數即可切換任務模式。
進階技巧:思維鏈提示(Chain-of-Thought Prompting)顯著提升復雜推理性能。
3、檢索增強生成(RAG)
外部知識實時注入:結合向量數據庫,在生成時動態檢索最新信息,解決幻覺問題的同時保持時效性。
效果對比:純生成式回答準確率約65%,RAG加持后可達90%+。
四、典型行業應用矩陣
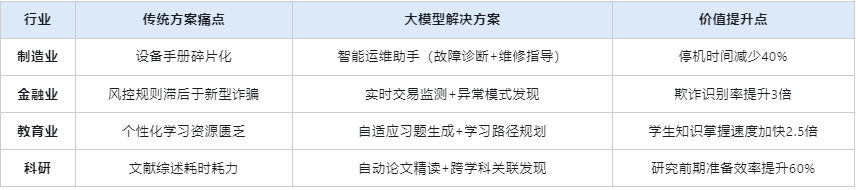
五、泛化能力的邊界與挑戰
當前限制:
分布外數據脆弱性:對抗樣本攻擊成功率仍達30%-50%
邏輯鏈條斷裂風險:超過5步的多跳推理錯誤率急劇上升
價值對齊偏差:不同文化背景下的道德判斷一致性不足
改進方向:
引入因果推理模塊強化邏輯嚴謹性
構建跨文化價值觀對齊數據集
開發不確定性量化輸出機制
大模型的泛化能力本質上是規模化帶來的認知涌現現象,其核心價值在于將人工智能從“專用工具”轉變為“通用認知接口”。未來隨著多模態預訓練、持續學習技術的發展,這種泛化能力將進一步突破現有邊界,真正實現“舉一反三”的機器智能。
- 上一篇:AI大模型的準確定義是什么?
- 下一篇:最后一篇
相關閱讀
- 人工智能與大模型的關系05-31
- DeepSeek火了,大模型的原生安全怎么做05-27
- 大模型對哪些行業產生了影響?05-19
- 大模型:人工智能的前沿05-13
- 大模型本地部署,如何構建AI安全體系?04-08
-

國際注冊信息安全專業人員CISSP認證
8月04-21日 在線咨詢 -

國家軟考高級-系統規劃與管理師
8月14-31日 在線咨詢 -

國家軟考高級-系統架構設計師
8月18-27日 在線咨詢 -

容器+Kubernetes認證管理員(CKA)
8月20-30日 在線咨詢 -

軟件工程造價師認證
8月20-22日 在線咨詢 -

CDSP數據安全認證專家
8月22-23日 在線咨詢 -

人工智能實踐項目案例分析與實戰應用
8月24-27日 在線咨詢 -

DAMA國際數據管理專業人士CDMP認證&DAMA中國數據治理工程師CDGA認證
8月25-27日 在線咨詢 -

數據資產管理師CDAM認證
8月26-28日 在線咨詢 -

國家注冊信息安全專業人員CISP認證
8月27-31日 在線咨詢 -

國家注冊信息安全專業人員CISP-PTE滲透測試工程師認證
8月27-31日 在線咨詢 -

ITSS-IT服務項目經理認證
8月27-29日 在線咨詢 -

ITSS-IT服務工程師認證
8月27-28日 在線咨詢 -

DAMA中國數據治理專家CDGP認證
8月28-30日 在線咨詢 -

網絡安全技術與攻防實戰
8月28-30日 在線咨詢 -

產品全生命周期管理運營與增長實戰
8月28-30日 在線咨詢
-
全國報名服務熱線
 400-626-7377
400-626-7377
-
熱門課程咨詢
 在線咨詢
在線咨詢
-
微信公眾號
 微信號:zpitedu
微信號:zpitedu
京ICP備13024721號-1
 京公網安備11010602007294號 增值電信業務經營許可證:京B2-20201348 全國統一報名專線:400-626-7377
京公網安備11010602007294號 增值電信業務經營許可證:京B2-20201348 全國統一報名專線:400-626-7377