
 400-626-7377
400-626-7377
中培專家論-卷積神經(jīng)網(wǎng)絡(luò)(CNN)介紹與實(shí)踐
1.1.大腦
作為人類,我們不斷地通過眼睛來觀察和分析周圍的世界,我們不需要刻意的“努力”思考,就可以對(duì)所看到的一切做出預(yù)測(cè),并對(duì)它們采取行動(dòng)。當(dāng)我們看到某些東西時(shí),我們會(huì)根據(jù)我們過去學(xué)到的東西來標(biāo)記每個(gè)對(duì)象。為了說明這些情況。
你可能會(huì)想到“這是一個(gè)快樂的小男孩站在椅子上”。或者也許你認(rèn)為他看起來像是在尖叫,即將在他面前攻擊這塊蛋糕。
這就是我們整天下意識(shí)地做的事情。我們看到事物,然后標(biāo)記,進(jìn)行預(yù)測(cè)和識(shí)別行為。但是我們?cè)趺醋龅竭@些的呢?我們?cè)趺茨芙忉屛覀兛吹降囊磺校?/p>
大自然花費(fèi)了5億多年的時(shí)間來創(chuàng)建一個(gè)系統(tǒng)來實(shí)現(xiàn)這一目標(biāo)。眼睛和大腦之間的合作,稱為主要視覺通路,是我們理解周圍世界的原因。
雖然視力從眼睛開始,但我們所看到的實(shí)際解釋發(fā)生在大腦的初級(jí)視覺皮層中。
當(dāng)您看到一個(gè)物體時(shí),您眼中的光感受器會(huì)通過視神經(jīng)將信號(hào)發(fā)送到正在處理輸入的主視覺皮層。在初級(jí)視覺皮層,使眼睛看到的東西的感覺。
所有這一切對(duì)我們來說都很自然。我們幾乎沒有想到我們能夠識(shí)別我們生活中看到的所有物體和人物的特殊性。神經(jīng)元和大腦連接的深層復(fù)雜層次結(jié)構(gòu)在記憶和標(biāo)記物體的過程中起著重要作用。
想想我們?nèi)绾螌W(xué)習(xí)例如傘是什么。或鴨子,燈,蠟燭或書。一開始,我們的父母或家人告訴我們直接環(huán)境中物體的名稱。我們通過給我們的例子了解到。慢慢地,但我們開始在我們的環(huán)境中越來越多地認(rèn)識(shí)到某些事情。它們變得如此普遍,以至于下次我們看到它們時(shí),我們會(huì)立即知道這個(gè)物體的名稱是什么。他們成為我們世界的模型一部分。
1.2.卷積神經(jīng)網(wǎng)絡(luò)的歷史
與孩子學(xué)會(huì)識(shí)別物體的方式類似,我們需要在能夠概括輸入并對(duì)之前從未見過的圖像進(jìn)行預(yù)測(cè)之前,展示數(shù)百萬張圖片的算法。
計(jì)算機(jī)以與我們不同的方式“看到”東西的。他們的世界只包括數(shù)字。每個(gè)圖像都可以表示為二維數(shù)字?jǐn)?shù)組,稱為像素。
但是它們以不同的方式感知圖像,這一事實(shí)并不意味著我們無法訓(xùn)練他們的識(shí)別模式,就像我們一樣如何識(shí)別圖像。我們只需要以不同的方式思考圖像是什么。
為了“教會(huì)”一種算法如何識(shí)別圖像中的對(duì)象,我們使用特定類型的人工神經(jīng)網(wǎng)絡(luò):卷積神經(jīng)網(wǎng)絡(luò)(CNN)。他們的名字源于網(wǎng)絡(luò)中最重要的一個(gè)操作:卷積。
卷積神經(jīng)網(wǎng)絡(luò)受到大腦的啟發(fā)。DH Hubel和TN Wiesel在20世紀(jì)50年代和60年代對(duì)哺乳動(dòng)物大腦的研究提出了哺乳動(dòng)物如何在視覺上感知世界的新模型。他們表明貓和猴的視覺皮層包括在其直接環(huán)境中專門響應(yīng)神經(jīng)元的神經(jīng)元。
在他們的論文中,他們描述了大腦中兩種基本類型的視覺神經(jīng)元細(xì)胞,每種細(xì)胞以不同的方式起作用:簡(jiǎn)單細(xì)胞(S細(xì)胞)和復(fù)合細(xì)胞(C細(xì)胞)。
例如,當(dāng)簡(jiǎn)單單元格將基本形狀識(shí)別為固定區(qū)域和特定角度的線條時(shí),它們就會(huì)激活。復(fù)雜細(xì)胞具有較大的感受野,其輸出對(duì)野外的特定位置不敏感。
復(fù)雜細(xì)胞繼續(xù)對(duì)某種刺激做出反應(yīng),即使它在視網(wǎng)膜上的絕對(duì)位置發(fā)生變化。在這種情況下,復(fù)雜指的是更靈活。
在視覺中,單個(gè)感覺神經(jīng)元的感受區(qū)域是視網(wǎng)膜的特定區(qū)域,其中某些東西將影響該神經(jīng)元的發(fā)射(即,將激活神經(jīng)元)。每個(gè)感覺神經(jīng)元細(xì)胞都有相似的感受野,它們的田地覆蓋著。
此外,層級(jí)【hierarchy 】的概念在大腦中起著重要作用。信息按順序存儲(chǔ)在模式序列中。的新皮層,它是大腦的最外層,以分層方式存儲(chǔ)信息。它存儲(chǔ)在皮質(zhì)柱中,或者在新皮層中均勻組織的神經(jīng)元分組。
1980年,一位名為Fukushima的研究員提出了一種分層神經(jīng)網(wǎng)絡(luò)模型。他稱之為新認(rèn)知。該模型的靈感來自簡(jiǎn)單和復(fù)雜細(xì)胞的概念。neocognitron能夠通過了解物體的形狀來識(shí)別模式。
后來,1998年,卷心神經(jīng)網(wǎng)絡(luò)被Bengio,Le Cun,Bottou和Haffner引入。他們的第一個(gè)卷積神經(jīng)網(wǎng)絡(luò)稱為L(zhǎng)eNet-5,能夠?qū)κ謱憯?shù)字中的數(shù)字進(jìn)行分類。
2、卷積神經(jīng)網(wǎng)絡(luò)
卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network)簡(jiǎn)稱CNN,CNN是所有深度學(xué)習(xí)課程、書籍必教的模型,CNN在影像識(shí)別方面的為例特別強(qiáng)大,許多影像識(shí)別的模型也都是以CNN的架構(gòu)為基礎(chǔ)去做延伸。另外值得一提的是CNN模型也是少數(shù)參考人的大腦視覺組織來建立的深度學(xué)習(xí)模型,學(xué)會(huì)CNN之后,對(duì)于學(xué)習(xí)其他深度學(xué)習(xí)的模型也很有幫助,本文主要講述了CNN的原理以及使用CNN來達(dá)成99%正確度的手寫字體識(shí)別。
CNN的概念圖如下:
從上面三張圖片我們可以看出,CNN架構(gòu)簡(jiǎn)單來說就是:圖片經(jīng)過各兩次的Convolution, Pooling, Fully Connected就是CNN的架構(gòu)了,因此只要搞懂Convolution, Pooling, Fully Connected三個(gè)部分的內(nèi)容就可以完全掌握了CNN!
2.1. convolution layer 卷積層
卷積運(yùn)算就是將原始圖片的與特定的Feature Detector(filter)做卷積運(yùn)算(符號(hào)?),卷積運(yùn)算就是將下圖兩個(gè)3x3的矩陣作相乘后再相加,以下圖為例0 *0 + 0*0 + 0*1+ 0*1 + 1 *0 + 0*0 + 0*0 + 0*1 + 0*1 =0
每次移動(dòng)一步,我們可以一次做完整張表的計(jì)算,如下:
下面的動(dòng)圖更好地解釋了計(jì)算過程:
左:過濾器在輸入上滑動(dòng)。右:結(jié)果匯總并添加到要素圖中。
中間的Feature Detector(Filter)會(huì)隨機(jī)產(chǎn)生好幾種(ex:16種),F(xiàn)eature Detector的目的就是幫助我們萃取出圖片當(dāng)中的一些特征(ex:形狀),就像人的大腦在判斷這個(gè)圖片是什么東西也是根據(jù)形狀來推測(cè)
利用Feature Detector萃取出物體的邊界
利用Feature Detector萃取出物體的邊界
使用Relu函數(shù)去掉負(fù)值,更能淬煉出物體的形狀
我們?cè)谳斎肷线M(jìn)行了多次卷積,其中每個(gè)操作使用不同的過濾器。這導(dǎo)致不同的特征映射。最后,我們將所有這些特征圖放在一起,作為卷積層的最終輸出。
就像任何其他神經(jīng)網(wǎng)絡(luò)一樣,我們使用激活函數(shù)使輸出非線性。在卷積神經(jīng)網(wǎng)絡(luò)的情況下,卷積的輸出將通過激活函數(shù)。這可能是ReLU激活功能
這里還有一個(gè)概念就是步長(zhǎng),Stride是每次卷積濾波器移動(dòng)的步長(zhǎng)。步幅大小通常為1,意味著濾鏡逐個(gè)像素地滑動(dòng)。通過增加步幅大小,您的濾波器在輸入上滑動(dòng)的間隔更大,因此單元之間的重疊更少。
下面的動(dòng)畫顯示步幅大小為1。
由于feature map的大小始終小于輸入,我們必須做一些事情來防止我們的要素圖縮小。這是我們使用填充的地方。
添加一層零值像素以使用零環(huán)繞輸入,這樣我們的要素圖就不會(huì)縮小。除了在執(zhí)行卷積后保持空間大小不變,填充還可以提高性能并確保內(nèi)核和步幅大小適合輸入。
可視化卷積層的一種好方法如下所示,最后我們以一張動(dòng)圖解釋下卷積層到底做了什么
卷積如何與K = 2濾波器一起工作,每個(gè)濾波器具有空間范圍F = 3,步幅S = 2和輸入填充P = 1.
2.2.pooling layer 池化層
在卷積層之后,通常在CNN層之間添加池化層。池化的功能是不斷降低維數(shù),以減少網(wǎng)絡(luò)中的參數(shù)和計(jì)算次數(shù)。這縮短了訓(xùn)練時(shí)間并控制過度擬合。
最常見的池類型是max pooling,它在每個(gè)窗口中占用最大值。需要事先指定這些窗口大小。這會(huì)降低特征圖的大小,同時(shí)保留重要信息。
Max Pooling主要的好處是當(dāng)圖片整個(gè)平移幾個(gè)Pixel的話對(duì)判斷上完全不會(huì)造成影響,以及有很好的抗雜訊功能。
2.3.Fully Connected Layer 全連接層
基本上全連接層的部分就是將之前的結(jié)果平坦化之后接到最基本的神經(jīng)網(wǎng)絡(luò)了
3、利用CNN識(shí)別MNIST手寫字體
下面這部分主要是關(guān)于如何使用tensorflow實(shí)現(xiàn)CNN以及手寫字體識(shí)別的應(yīng)用:
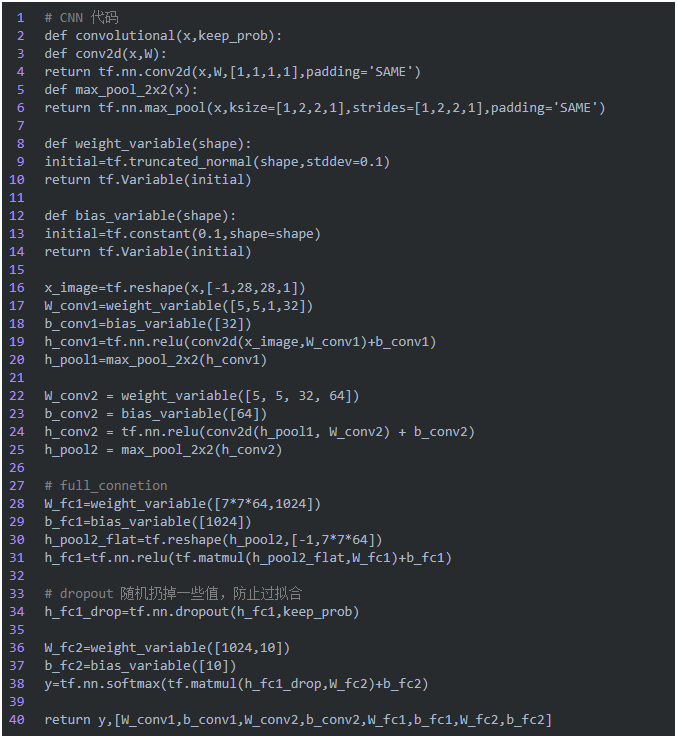
大家稍微對(duì)tensorflow的代碼有些基礎(chǔ),理解上面這部分基本上沒有難度,并且基本也是按照我們前面概念圖中的邏輯順序?qū)崿F(xiàn)的。
最終按照慕課網(wǎng)上的學(xué)習(xí)資料TensorFlow與Flask結(jié)合打造手寫體數(shù)字識(shí)別,實(shí)現(xiàn)了一遍CNN,比較曲折的地方是前端,以 及如何將訓(xùn)練的模型與flask整合,最后項(xiàng)目效果如下:
4、總結(jié)
最后說自己的兩點(diǎn)感觸吧:
1、CNN在各種場(chǎng)景已經(jīng)應(yīng)用很成熟,網(wǎng)上資料特別多,原先自己也是略知一二,但是從來沒有總結(jié)整理過,還是整理完之后心里比較踏實(shí)一些。
2、切記理論加實(shí)踐,實(shí)現(xiàn)一遍更踏實(shí)。
想了解更多IT資訊,請(qǐng)?jiān)L問中培偉業(yè)官網(wǎng):中培偉業(yè)
- 上一篇:企業(yè)數(shù)字化轉(zhuǎn)型頂層設(shè)計(jì)(togaf認(rèn)證)調(diào)研階段/評(píng)估階段/呈現(xiàn)階段/交付階段
- 下一篇:中培專家分析探索信息化困局和總體架構(gòu)設(shè)計(jì)(togaf認(rèn)證)采集必要的基礎(chǔ)信息
相關(guān)閱讀
-

網(wǎng)絡(luò)安全技術(shù)與攻防實(shí)戰(zhàn)
7月09-11日 在線咨詢 -

PMP項(xiàng)目管理國(guó)際認(rèn)證
7月14-07日 在線咨詢 -

國(guó)家軟考高級(jí)-系統(tǒng)分析師
7月17-06日 在線咨詢 -

ITSS-IT服務(wù)項(xiàng)目經(jīng)理認(rèn)證
7月23-25日 在線咨詢 -

ITSS-IT服務(wù)工程師認(rèn)證
7月23-24日 在線咨詢 -

AI重塑辦公-Deepseek助力職場(chǎng)辦公效能提升全攻略
7月23-24日 在線咨詢 -

TOGAF?EA理論與實(shí)踐鑒定級(jí)認(rèn)證
7月24-27日 在線咨詢 -

DeepSeek大模型應(yīng)用開發(fā)最佳實(shí)踐
7月25-27日 在線咨詢 -

國(guó)家注冊(cè)信息安全專業(yè)人員CISP認(rèn)證
7月26-30日 在線咨詢 -

國(guó)際注冊(cè)信息系統(tǒng)審計(jì)師CISA認(rèn)證
7月26-30日 在線咨詢 -

數(shù)據(jù)治理、數(shù)據(jù)架構(gòu)設(shè)計(jì)及數(shù)據(jù)標(biāo)準(zhǔn)化方法
7月28-30日 在線咨詢 -

AI賦能項(xiàng)目管理-從需求到管理落地,對(duì)標(biāo)巨頭實(shí)戰(zhàn)
7月28-31日 在線咨詢 -

業(yè)務(wù)需求分析及產(chǎn)品設(shè)計(jì)實(shí)戰(zhàn)
7月28-30日 在線咨詢 -

云原生架構(gòu)與容器化部署實(shí)戰(zhàn)訓(xùn)練營(yíng)
7月28-30日 在線咨詢
-
全國(guó)報(bào)名服務(wù)熱線
 400-626-7377
400-626-7377
-
熱門課程咨詢
 在線咨詢
在線咨詢
-
微信公眾號(hào)
 微信號(hào):zpitedu
微信號(hào):zpitedu
京ICP備13024721號(hào)-1
 京公網(wǎng)安備11010602007294號(hào) 增值電信業(yè)務(wù)經(jīng)營(yíng)許可證:京B2-20201348 全國(guó)統(tǒng)一報(bào)名專線:400-626-7377
京公網(wǎng)安備11010602007294號(hào) 增值電信業(yè)務(wù)經(jīng)營(yíng)許可證:京B2-20201348 全國(guó)統(tǒng)一報(bào)名專線:400-626-7377